


The AI-Native Cloud: How to Build Platforms That Learn Faster Than Your Competition

AI has outgrown the demo stage. In 2025, it powers search, support, analytics, personalization, and ops quietly, reliably, and under strict budgets. The companies winning don’t bolt AI onto brittle stacks; they build AI-native platforms that make the right thing the easy thing. That shift is architectural and operational: data becomes a governed product, retrieval is a shared service, models are a managed portfolio, and safety and cost controls are part of CI/CD. The difference between a string of PoCs and a durable advantage often comes from disciplined platform engineering plus the pattern library an experienced aws cloud consultant brings, reinforced by a cloud technology consultant who codifies guardrails that teams actually adopt.
What “AI-Native” Really Means in 2025
AI-native is not “we use an LLM.” It’s a platform with repeatable primitives that any product team can combine to ship dependable features quickly. The critical building blocks are: an access-aware retrieval layer, a router that chooses the right model by task and budget, a versioned prompt and policy registry, continuous evaluation pipelines, and deep observability that explains behavior. These components live behind well-documented APIs and are discoverable through a developer portal so use cases scale without re-architecting.
The RAG Spine: Modular, Swappable, Observable
Retrieval-augmented generation (RAG) is the default backbone because it grounds outputs in your facts, reduces hallucinations, and preserves privacy. In production, RAG is four decoupled services you can evolve independently:
- Retriever: Hybrid search that blends keyword, vector, and often graph signals. Documents are chunked by domain semantics—sections, tables, entities—and enriched with metadata for access control and recency.
- Router: A policy-driven decision-maker that selects models based on complexity, sensitivity, latency budget, and token caps.
- Generator: Strict prompt templates with structure, tone, and refusal rules, plus support for tool calling where actions are required.
- Policy Layer: Deterministic checks for PII masking, regulated term handling, formatting compliance, and escalation to human review when thresholds are crossed.
A seasoned aws cloud consultant will help keep these seams clean so you can replace the retriever or swap models without rewiring the entire app.
Data Is the Differentiator—Engineer It Like Software
Your competitive moat is the data others can’t copy. Treat it like code: define contracts, owners, SLAs, and quality checks (not-null, uniqueness, distribution, freshness). Maintain lineage from source system to prompt context with transformation code versions and parameters. For documents, store citation anchors (document IDs, sections, timestamps) so responses can show sources and audits can reconstruct “why the model said that.” A cloud technology consultant will push for data products with self-serve documentation and access approvals that resolve in minutes, not weeks.
Model Portfolio Strategy: Quality Without Open-Ended Costs
No single model is optimal across all tasks. The pragmatic approach is a portfolio with clear roles:
- Small, fast models handle routing, classification, short summaries, and “first-pass” answers.
- Mid-sized models cover most synthesis and reasoning where latency and cost matter.
- Larger models are reserved for complex, high-stakes tasks or creative synthesis.
Budget-aware routing ensures premium models serve high-value requests while smaller models shoulder volume. Over time, fine-tuned small models capture more traffic, cutting cost and latency without sacrificing accuracy. An aws cloud consultant can codify these heuristics and wire in graceful fallbacks when budgets or rate limits are hit.
Prompts, Retrieval, and Policies as Code
Prompts are not strings; they’re versioned artifacts with tests, owners, and changelogs. The same applies to retrieval parameters and policy rules. Treat these like application code:
- Keep them in version control.
- Write unit tests for structure, safety refusals, and format adherence.
- Use canary releases that send a slice of real traffic to new versions and auto-roll back on regression.
- Attach release notes that product and compliance can read.
This discipline is what turns subjective “prompt craft” into an engineering practice teams can trust.
Safety You Can Prove
Safety is layered, auditable, and boring in the best way. Start with prompt constraints and clear refusal guidance. Add retrieval filters based on user entitlements. Apply content classifiers for PII, hate, or regulated topics. Enforce a deterministic policy engine that masks sensitive data and blocks or routes risky outputs to human approval. Log prompts, retrieved context fingerprints, model versions, router decisions, and policy actions with selective redaction. Those logs—structured, searchable, and retained by policy—are your audit evidence and your fastest path through security reviews.
Observability That Explains Behavior, Not Just Uptime
Traditional APM tells you if the API works; AI-native observability tells you why answers changed.
- Retrieval coverage: proportion of queries with high-quality context.
- Grounding scores: alignment between output and retrieved passages.
- Token usage: by component, route, and tenant.
- Latency breakdowns: retrieval vs. generation vs. post-processing.
- Quality evals: judge-model scores and human spot checks for high-stakes flows.
Dashboards should be per use case, not just per service, so product owners see quality and cost next to latency. When metrics dip, your telemetry should pinpoint whether retrieval drifted, the router misclassified, a model updated, or a prompt change regressed.
Cost Discipline Without Killing UX
Token and context costs can balloon quietly. Controls that work in the real world include citation-aware truncation, semantic chunking that reduces context bloat, caching embeddings and frequent answers with appropriate TTLs, and enforcing route-level budgets. For repetitive workloads, fine-tune smaller models or use adapters to approximate large-model quality at a fraction of the price. A pragmatic cloud technology consultant will also add cost previews to design reviews so you catch expensive patterns early.
Security, Privacy, and Residency by Construction
Keep sensitive processing inside private networks with workload identity and short-lived credentials. Enforce attribute-based access control at retrieval time so users see only what they’re entitled to. Partition indices by region and route traffic in compliance with residency laws. Encrypt everywhere with centralized key policies; treat logs, caches, and analytics exports (the “shadow data”) with the same rules. These are platform features, not one-off exceptions.
Organizational Design: Make the Platform a Product
AI-native success depends on roles and rituals:
- Platform team owns shared services: retrieval, routing, prompts/policies, evaluation, and observability.
- Domain teams own use cases and map acceptance criteria to evaluation metrics and safety policies.
- Security writes policies as code and participates in pre-prod checks, not after-the-fact reviews.
- SMEs curate evaluation sets and canonical sources.
A lightweight governance board reviews new AI features against a checklist: data sources, safety plan, evaluation metrics, fallback strategy, cost guardrails, and residency. This speeds approvals and avoids surprises.
A 180-Day Execution Plan You Can Actually Run
- Days 1–30: Pick one high-impact, low-risk use case. Stand up the retrieval service, prompt/policy registry, router, and basic evaluation harness. Instrument grounding and token metrics.
- Days 31–60: Ship to a pilot cohort with canary prompts and budget-aware routing. Add structured output validation, PII masking, and human-in-the-loop for risky paths.
- Days 61–90: Expand to a second use case. Introduce automated evaluations on every meaningful change (retriever, prompt, model, router). Add cost previews to design reviews.
- Days 91–120: Fine-tune a small model for a high-volume task to reduce spend and latency. Add per-tenant budgets and graceful degradation strategies.
- Days 121–180: Roll out a developer portal with paved-road templates. Formalize residency-aware indices. Conduct an AI incident drill (retrieval drift, model update) and publish learnings.
By month six, you should be adding new AI features in weeks with predictable quality and cost.
Example Scenarios That Pay Off Fast
- Support Assist: Grounded Q&A with citations and deflection suggestions. Small models handle routing and FAQ; larger models tackle novel queries. Outcome: higher first-contact resolution and controlled token spend.
- Sales Intelligence: Summarize account activity, risk signals, and next best actions from curated CRM and usage data. Outcome: reduced prep time, better pipeline hygiene.
- Ops Command Copilot: Natural-language runbooks with tool use under policy. Outcome: faster mean time to mitigate with auditable actions.
An aws cloud consultant will lift these from slideware to production by wiring the platform primitives, while a cloud technology consultant will ensure guardrails, logging, and evaluation satisfy security and compliance.
Common Pitfalls—and Better Alternatives
- Pitfall: One giant model for everything. Better: Portfolio with routing; fine-tune smaller models for narrow, high-volume tasks.
- Pitfall: Stuffing huge contexts to “improve quality.” Better: Smarter retrieval, semantic chunking, and citation-aware truncation.
- Pitfall: Prompts as ad-hoc strings. Better: Versioned prompts with tests, canaries, and rollbacks.
- Pitfall: Rebuilding bespoke stacks per team. Better: Shared services for retrieval, routing, prompts/policies, and evals—with paved-road templates.
- Pitfall: Monthly cost surprises. Better: Budget-aware routing, cost previews in design, and route-level alerts to owners.
Measuring ROI Leaders Believe
Tie the program to unit economics: cost per resolved query, cost per generated summary, cost per inference by route, and incremental conversion or retention. Pair these with quality and latency: grounding, factuality, safety compliance, and p95 response time. These metrics turn tradeoffs into informed choices—some flows justify premium models; most don’t.
Conclusion
AI-native platforms are how 2025 teams move from experiments to compounding advantage. Build a modular RAG spine, manage models as a portfolio, treat prompts and policies as code, observe behavior deeply, and keep costs tied to value. With the blueprint and discipline brought by an aws cloud consultant and the operating model a cloud technology consultant helps encode, you can ship AI features that are grounded, safe, fast, and affordable again and again, across your entire product surface.
Категории
Больше
Explore stunning Front elevation Design ideas with House Gyan and transform your home's appearance. Our expert-curated Elevation Design concepts combine style, function, and modern aesthetics to give your house a striking look. Whether you're building a new home or renovating, our House Front Design suggestions suit all architectural styles and budgets. From contemporary to traditional facades,...

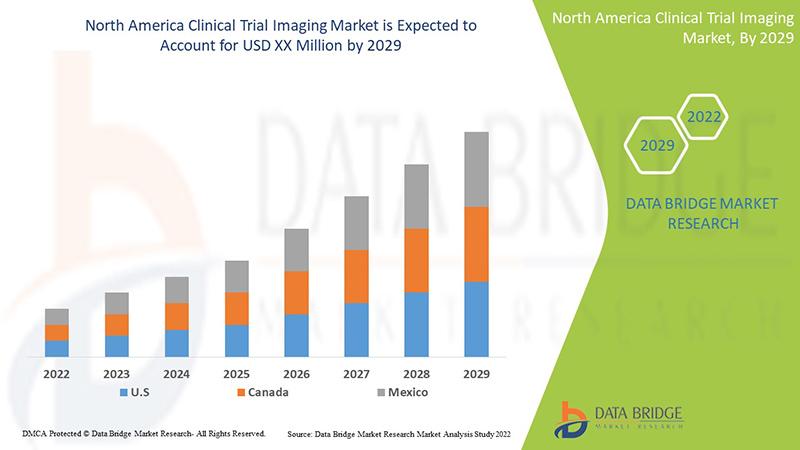
"Global Executive Summary North America Clinical Trial Imaging Market: Size, Share, and Forecast The rising technological progressions in clinical trial imaging for diagnosis and treatment of chronic diseases are expected to drive market growth. Data Bridge Market Research analyzes that the North America clinical trial imaging market will grow at a CAGR of 8.3% during the forecast period...
Introduction The nose plays a central role in defining the balance and harmony of the face. For many individuals, reshaping or refining it can significantly improve confidence and overall appearance. Rhinoplasty plastic surgery in NCR has become a popular choice, offering both cosmetic and functional benefits. Whether you wish to correct a medical concern or enhance facial aesthetics, NCR...
Executive Summary Europe Edible Oil Market : The Europe edible oil market size was valued at USD 15.44 billion in 2024 and is expected to reach USD 24.06 billion by 2032, at a CAGR of 5.70% during the forecast period Europe Edible Oil Market analysis report is a professional and a detailed market study focusing on primary and secondary drivers,...
Looking for guidance in life? Astrologer Ganga is recognized as the Famous Astrologer in Perth and trusted as the Best Astrologer in Perth for providing accurate readings, spiritual remedies, and personalized solutions. Known as the Top Astrologer in Perth, he helps people overcome love, career, family, and business challenges with powerful Vedic astrology practices. Astrology has always been a...

